Code
mi_funcion <- function(parametros){
acciones
resultado a regresar
}Las funciones reúnen una secuencia de operaciones como un todo, almacenando para su uso continuo. Las funciones proveen:
Como el componente básico de la mayoría de los lenguajes de programación, las funciones definidas por el usuario constituyen la “programación” de cualquier abstracción que puedas hacer.
Si has escrito una función, eres ya todo un programador.

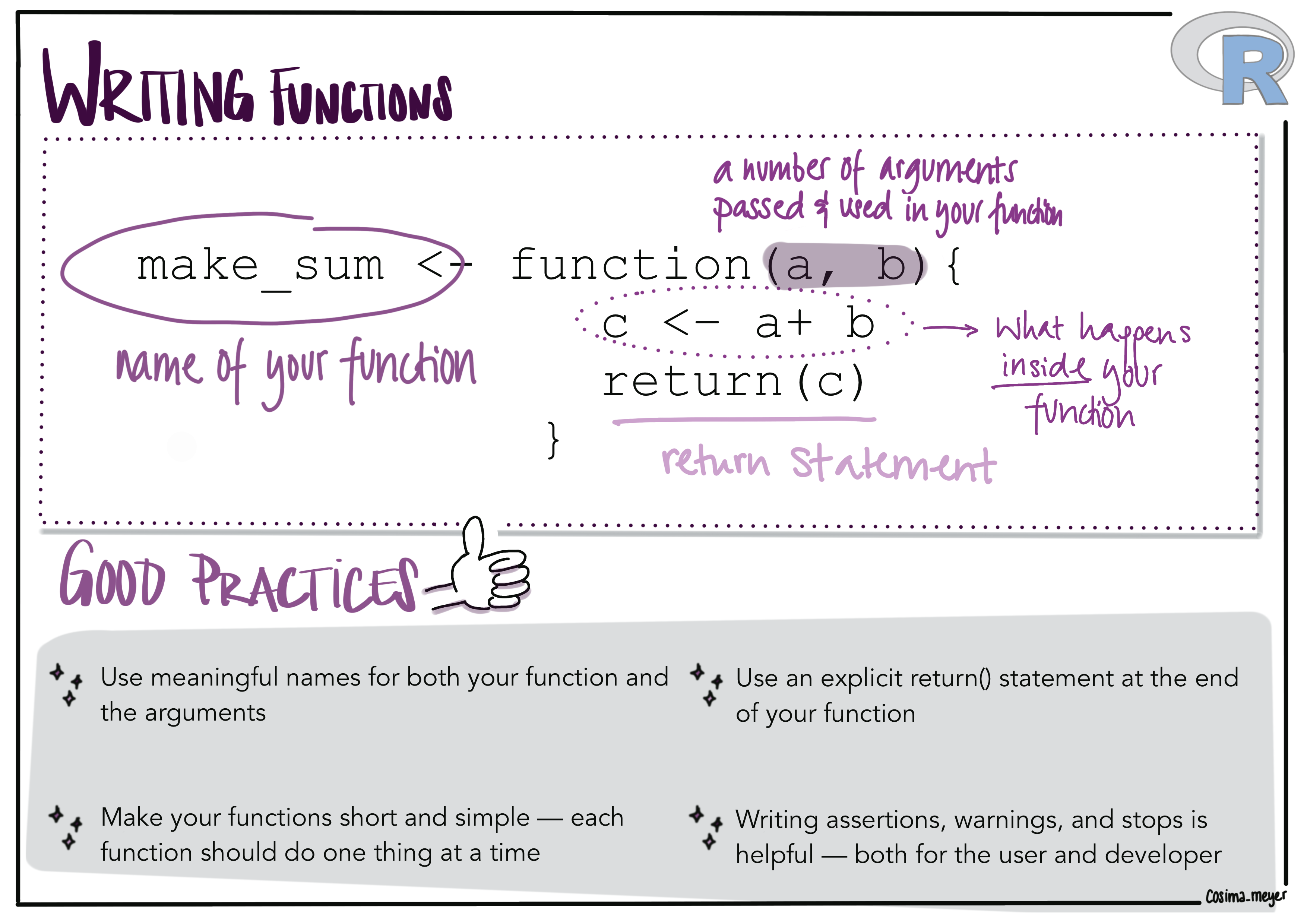
En R al igual que en otros lenguajes de programación podemos crear nuestras propias funciones.
La estructura de una función en R es la siguiente:
mi_funcion <- function(parametros){
acciones
resultado a regresar
}Las estructuras de control más usadas:
| Estructura de control | Descripción |
|---|---|
if, else |
Si, de otro modo |
for |
Para cada uno en |
while |
Mientras |
break |
Interrupción |
next |
Siguiente |
case_when |
Conducional con diversas salidas |
if, elseif (si) es usado cuando deseamos que una operación se ejecute únicamente cuando una condición se cumple.
else (de otro modo) es usado para indicarle a R qué hacer en caso de la condición de un if no se cumpla.
IF you are happy THEN
smile
ELSE
frown
ENDIFSi se cumple la condición y se muestra “Verdadero”
if(4 > 3) {
"Verdadero"
} else {
"Falso"
}[1] "Verdadero"
for (for loop)Su estructura es la siguiente:
for(elemento in objeto) {
operacion_con_elemento
}Con lo anterior le decimos a R:
Vamos a obtener el cuadrado de cada uno de los elementos en un vector numérico del 1 al 6, que representa las caras de un dado.
dado <- 1:6
mi_vector <- NULL # variable de almacen, vector vacio
# Cara es el contador, que agarra CADA valor de dado
# Empezando con 1 hasta el 6, teniendo 6 iteraciones
for(cara in dado) {
mi_vector[cara] <- cara ^ 2
}
mi_vector[1] 1 4 9 16 25 36whileEste es un tipo de bucle que ocurre mientras una condición es verdadera (TRUE). La operación se realiza hasta que se se llega a cumplir un criterio previamente establecido.
El modelo de while es:
while(condicion){
operaciones
}Con esto le decimos a R:
La condición generalmente es expresada como el resultado de una o varias operaciones de comparación, pero también puede ser el resultado de una función.
Ejemplo:
Primero, tomará un número al azar del 1 al 10, y lo sumará a valor.
Segundo, le sumará 1 a conteo cada que esto ocurra, de esta manera sabremos cuántas iteraciones ocurrieron para llegar a un valor que no sea menor a 50.
# declarar dos vectores vacios
conteo <- 0
valor <- 0
while(valor < 50) {
# Sample va UN valor aleatorio de 1 a 10
valor <- valor + sample(x = 1:10, size = 1)
conteo <- conteo + 1
}
valor[1] 54conteo[1] 9El ciclo se va a repetir mientras valor sea menos a 50.
conteo <- 0
while("dado" == "ficha") {
conteo <- conteo + 1
}
conteo[1] 0break y nextbreak y next son palabras reservadas en R, no podemos asignarles nuevos valores y realizan una operación específica cuando aparecen en nuestro código.
break nos permite interrumpir un bucle, mientras que next nos deja avanzar a la siguiente iteración del bucle, “saltándose” la actual. Ambas funcionan para for y while.
breakPara interrumpir un bucle con break, necesitamos que se cumpla una condición. Cuando esto ocurre, el bucle se detiene, aunque existan elementos a los cuales aún podría aplicarse.
Interrumpimos un for cuando i es igual a 3, aunque aún queden 7 elementos en el objeto.
for(i in 1:10) {
if(i == 3) {
break
}
print(i)
}[1] 1
[1] 2break y whilenumero <- 20
while(numero > 5) {
if(numero == 15) {
break
}
numero <- numero - 1
}
numero[1] 15nextPor su parte, usamos next para “saltarnos” una iteración en un bucle. Cuando la condición se cumple, esa iteración es omitida.
for(i in 1:4) {
if(i == 3) {
next
}
print(i)
}[1] 1
[1] 2
[1] 4case_when()Esquema general:
INPUT color
CASE color of
red: PRINT "red"
green: PRINT "green"
blue: PRINT "blue"
OTHERS
PRINT "Please enter a value color"
ENDCASEEjemplo:
library(dplyr)
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionx <- 1:20
case_when(
x %% 35 == 0 ~ "fizz buzz",
x %% 5 == 0 ~ "fizz",
x %% 7 == 0 ~ "buzz",
.default = as.character(x)
) [1] "1" "2" "3" "4" "fizz" "6" "buzz" "8" "9" "fizz"
[11] "11" "12" "13" "buzz" "fizz" "16" "17" "18" "19" "fizz"La fundación Gapminder7 es una organización sin fines de lucro con sede en Suecia que promueve el desarrollo global mediante el uso de estadísticas que pueden ayudar a reducir mitos comunes e historias sensasionalistas sobre la salud y la economía mundial. Una selección importante de datos ya está cargada en la librería dslabs en el data frame gapminder.
Formular preguntas es una forma muy útil de limitar el numero exponencial de caminos a tomar, en particular las preguntas concisas y las hipótesis pueden servir para eliminar el numero de dimensiones y variables que nos son inmediatamente relevantes para responderlas.
Las siguientes preguntas se toman cómo ejemplo para nuestro análisis:
library(gapminder) # paquete de cran
library(tidyverse)── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ forcats 1.0.0 ✔ readr 2.1.5
✔ ggplot2 3.5.1 ✔ stringr 1.5.1
✔ lubridate 1.9.3 ✔ tibble 3.2.1
✔ purrr 1.0.2 ✔ tidyr 1.3.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsgap <- gapminder
head(gap)# A tibble: 6 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.str(gap)tibble [1,704 × 6] (S3: tbl_df/tbl/data.frame)
$ country : Factor w/ 142 levels "Afghanistan",..: 1 1 1 1 1 1 1 1 1 1 ...
$ continent: Factor w/ 5 levels "Africa","Americas",..: 3 3 3 3 3 3 3 3 3 3 ...
$ year : int [1:1704] 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 ...
$ lifeExp : num [1:1704] 28.8 30.3 32 34 36.1 ...
$ pop : int [1:1704] 8425333 9240934 10267083 11537966 13079460 14880372 12881816 13867957 16317921 22227415 ...
$ gdpPercap: num [1:1704] 779 821 853 836 740 ...¿Qué nos dicen las columnas?
Una vez que determinamos que nuestra data esta completa y que conocemos la estructura de nuestras variables, podemos limpiar nuestra información, revisando los formatos de fechas, quitando NA’s y NULL, así como eliminar la información que no arroja valor para responder nuestras preguntas.
EDA <- gap %>%
select(country, year, lifeExp)
head(EDA)# A tibble: 6 × 3
country year lifeExp
<fct> <int> <dbl>
1 Afghanistan 1952 28.8
2 Afghanistan 1957 30.3
3 Afghanistan 1962 32.0
4 Afghanistan 1967 34.0
5 Afghanistan 1972 36.1
6 Afghanistan 1977 38.4Nuestra primera aproximación sería realizar un ranking de los páises con la esperanza de vida más alta del 2007 lo cuál podemos realizarlo muy facilmente usando la función arrange().
Ranking <- EDA %>%
filter(year == 2007) %>%
arrange(desc(lifeExp))
head(Ranking)# A tibble: 6 × 3
country year lifeExp
<fct> <int> <dbl>
1 Japan 2007 82.6
2 Hong Kong, China 2007 82.2
3 Iceland 2007 81.8
4 Switzerland 2007 81.7
5 Australia 2007 81.2
6 Spain 2007 80.9Concluimos que la resuesta es Japón con 82.6 años
En este caso la solución requiere que hagamos ajustes a nuestra tabla para poder calcular una nueva variable llamada delta que es la diferencia entre la esperanza de vida del 2007 VS la de 2002.
# Extraer datos de 2002
Y2002 <- EDA %>%
filter(year == 2002) %>%
rename(LExp2002 = lifeExp) %>%
select(-year)
# Extraer datos de 2007
Y2007 <- EDA %>%
filter(year == 2007) %>%
rename(LExp2007 = lifeExp) %>%
select(-year)
# Unir informacion por columnas
LifeExpDelta <- merge(Y2002,Y2007)
# Obtener el valor de Delta (diferencia entre la esperanza de vida)
Delta <- LifeExpDelta %>%
mutate(delta = (LExp2007-LExp2002)/LExp2002) %>%
arrange(desc(delta))
head(Delta) country LExp2002 LExp2007 delta
1 Botswana 46.634 50.728 0.08779002
2 Zimbabwe 39.989 43.487 0.08747406
3 Zambia 39.193 42.384 0.08141760
4 Uganda 47.813 51.542 0.07799134
5 Malawi 45.009 48.303 0.07318536
6 Rwanda 43.413 46.242 0.06516481Botswana es el pais con el aumento mas drastico en la esperanza de vida.
gap %>%
group_by(continent, country) %>%
select(country, year, continent, lifeExp) %>%
mutate(le_delta = lifeExp - lag(lifeExp, 1)) %>%
summarize(best_le_delta = max(le_delta, na.rm = TRUE)) %>%
arrange(-best_le_delta) %>%
head(5)`summarise()` has grouped output by 'continent'. You can override using the
`.groups` argument.# A tibble: 5 × 3
# Groups: continent [3]
continent country best_le_delta
<fct> <fct> <dbl>
1 Asia Cambodia 19.7
2 Asia China 13.9
3 Africa Rwanda 12.5
4 Africa Mauritius 7.10
5 Europe Bulgaria 7.01gap %>%
group_by(continent, country) %>%
select(country, year, continent, lifeExp) %>%
mutate(le_delta = lifeExp - lag(lifeExp, 1)) %>%
summarize(worst_le_delta = min(le_delta, na.rm = TRUE)) %>%
arrange(worst_le_delta) %>%
head(5)`summarise()` has grouped output by 'continent'. You can override using the
`.groups` argument.# A tibble: 5 × 3
# Groups: continent [1]
continent country worst_le_delta
<fct> <fct> <dbl>
1 Africa Rwanda -20.4
2 Africa Zimbabwe -13.6
3 Africa Lesotho -11.0
4 Africa Swaziland -10.4
5 Africa Botswana -10.2